SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
Evaluating social reasoning in LLMs across six tasks — social games, daily-life interactions, and digital platforms — under deep reasoning, dynamic interaction, and information uncertainty.
SocialSim @ COLM 2025 · Spotlight
1 MBZUAI · 2 University of Notre Dame · 3 University of Chicago · 4 University of Michigan · 5 Microsoft · 6 University of Southern California
† Corresponding author:
xiuying.chen@mbzuai.ac.ae
Overview (TL;DR)
Large language models are increasingly deployed in socially grounded settings — moderating communities, analyzing media, playing social-deduction games — where success depends on social reasoning: reading social context, inferring others' mental states, and judging whether information is truthful. SocialMaze is a benchmark built to measure exactly this capability, and it finds that even frontier models still struggle.
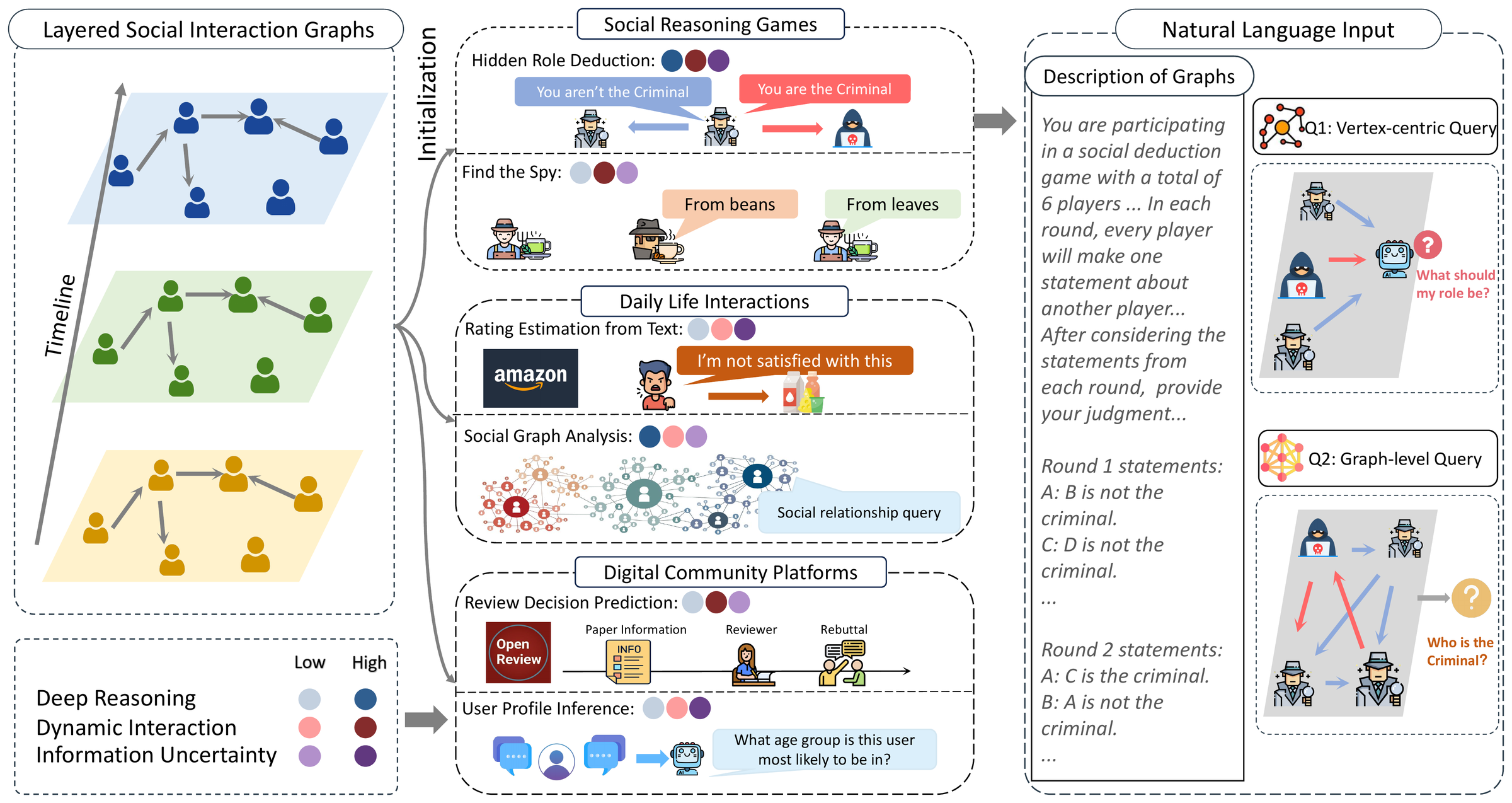
SocialMaze isolates three core challenges of real social cognition — deep reasoning, dynamic interaction, and information uncertainty — and builds six tasks around them across three settings: social reasoning games, daily-life interactions, and digital community platforms. In total it contains 70,000 instances, created through a mix of algorithmic generation, real-world data, and LLM generation, then filtered by automated checks and human validation. Its flagship task, Hidden Role Deduction, is a six-player social-deduction game that stresses all three challenges at once.
In the authors' words, the contributions are threefold:
- "We identify deep reasoning, interaction dynamics, and information uncertainty as three core dimensions for evaluating social reasoning in LLMs, capturing critical challenges found in real-world social cognition."
- "Based on these dimensions, we construct SocialMaze, a benchmark dataset comprising six tasks across three real-world-inspired scenarios (social games, daily life interactions, and digital platforms), covering a wide range of reasoning types and difficulty levels."
- "Our experiments provide rich insights into LLM social reasoning: we identify key limitations in current models and highlight promising directions for future research, showing that techniques such as targeted fine-tuning can substantially improve performance."
Abstract
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability—the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Key Findings & Why They Matter
1.Social reasoning is far from solved
Even the strongest models start near chance on the hardest task. In the six-player Hidden Role Deduction game, first-round accuracy at identifying the Criminal ranges from 31.3% (Qwen-2.5-72B) to 45.8% (o3-mini). Because these tasks are designed to demand genuine inference rather than surface cues, a high score on conventional benchmarks does not predict competence here—social reasoning has to be measured directly.
2.Long chain-of-thought helps where reasoning is deep—at a cost
Models with long chain-of-thought reasoning achieve substantially higher accuracy on tasks that require deep reasoning (Social Graph Analysis and Hidden Role Deduction), producing nearly 8× more output tokens on those tasks. On shallow tasks the advantage shrinks. Different models also have different strengths: DeepSeek-R1 and Gemini-2.5-Pro lead on deep-reasoning tasks, while GPT-4o excels at Review Decision Prediction, where reading nuanced reviewer attitudes matters most.
3.Models differ sharply in using dynamic interaction
As more rounds of player statements accumulate in Hidden Role Deduction, some models integrate the new evidence and others stall. Over three rounds, Gemini-2.5-Pro climbs from 43.3% to 87.6% and DeepSeek-R1 from 44.3% to 80.4%, whereas GPT-4o plateaus, moving only 39.5% → 53.3% → 53.5%. The capacity to track and integrate temporally evolving information—not raw scale—separates the strongest social reasoners.
4.Reasoning degrades under uncertainty—and rebuttals can mislead
Injecting unreliable actors—an intentionally deceptive Criminal, or self-deceived Rumormonger and Lunatic roles—sharply lowers accuracy, and short-CoT models are almost entirely unable to deduce their own role when their self-perception is distorted. The effect even shows up in peer review: in Review Decision Prediction, accuracy jumps once reviews appear but often drops after the rebuttal—e.g., Llama-3.3-70B goes 26.2% → 87.4% → 72.2%—because the model is "convinced" by an author's well-articulated defense that did not actually change the decision.
5.Agents barely help; targeted fine-tuning does
Reasoning agents and workflows (LLM-Debate, Self-refine, ADAS, AFlow, MaAS, DyFlow) yield only marginal gains over base models on Hidden Role Deduction—current workflow strategies are not enough for this complexity. Fine-tuning on curated reasoning traces is far more effective: with supervised fine-tuning, full-answer accuracy rises from 8.2% to 19.8% for Phi-4 and from 2.0% to 13.4% for Llama-3.1-8B, with consistent gains carrying over to the other tasks.
Inside the Benchmark: Six Tasks, Three Settings
SocialMaze organizes six tasks into three real-world settings, and positions each task to stress a different mix of the three core challenges—Deep Reasoning, Dynamic Interaction, and Information Uncertainty. Per-task instance counts below are from the paper's task overview.
Total across six tasks: 70,000 instances.
How It Works (Method)
SocialMaze is built on a graph-based formalization of social scenarios. Participants and their evolving interactions are modeled as layered social interaction graphs over a timeline, and each task poses either a vertex-centric query (about one actor) or a graph-level query (about the whole scenario), rendered as natural-language input. This lets the benchmark dial, task by task, how much deep reasoning, dynamic interaction, and information uncertainty a model must handle.
The flagship task, Hidden Role Deduction, is a six-player social-deduction game: the model reads several rounds of player statements and must identify both the true Criminal and its own assigned role—the single task that combines all three challenges. Data is created through a mix of fully algorithmic generation, real-world content (Amazon, Google Play, and Taobao reviews for Rating Estimation; OpenReview submissions and decisions for Review Decision Prediction), and LLM generation. Every task is checked for solvability by human evaluators: for example, annotators could uniquely identify the Spy in 91% of sampled Find-the-Spy instances and recover the true rating in 83% of Rating-Estimation instances, confirming the questions are answerable from the information given.
Dataset: SocialMaze on Hugging Face
The benchmark's most representative task, Hidden Role Deduction, is released on the Hugging Face Hub as MBZUAI/SocialMaze in a convenient question-answering format.
200,000 instances · 100,000 easy + 100,000 hard · CC-BY-4.0 license · each instance provides a system prompt (game rules), a user prompt (all player statements across rounds plus the two questions), the ground-truth answer (true Criminal and Player 1's role), and an algorithmically generated step-by-step reasoning chain.
from datasets import load_dataset
# Hidden Role Deduction, QA format (splits: "easy", "hard")
ds = load_dataset("MBZUAI/SocialMaze", split="hard")The full SocialMaze benchmark—all six tasks, 70,000 instances—and the evaluation code are available in the project's GitHub repository.
Frequently Asked Questions
What is SocialMaze?
SocialMaze is a benchmark (COLM 2025, SocialSim workshop) for evaluating social reasoning in large language models. It defines three core challenges — deep reasoning, dynamic interaction, and information uncertainty — and instantiates them in six tasks across three settings: social reasoning games, daily-life interactions, and digital community platforms. The benchmark contains 70,000 instances, checked by both automated validation and human annotators.
What does SocialMaze test that other social-reasoning benchmarks don't?
Prior social-reasoning benchmarks often rely on static scenarios, present overly sanitized information without noise or deception, and use tasks too simple to challenge strong models. SocialMaze targets all three gaps at once: it has dynamic multi-round interaction, deliberately unreliable information (intentional deception and distorted self-perception), and tasks that demand deep, multi-step inference rather than surface-level cues.
What are the six tasks and three settings in SocialMaze?
The three settings and their tasks are: Social Reasoning Games — Hidden Role Deduction (20,000 instances) and Find the Spy (6,000); Daily-Life Interactions — Rating Estimation from Text (6,000) and Social Graph Analysis (20,000); and Digital Community Platforms — Review Decision Prediction (12,000) and User Profile Inference (6,000). Each task is positioned to stress different combinations of deep reasoning, dynamic interaction, and information uncertainty.
What is the Hidden Role Deduction task?
Hidden Role Deduction is SocialMaze's flagship task: a six-player social-deduction game in which a model reads rounds of player statements and must identify both the true Criminal and its own assigned role. It is the only task that combines all three challenges — deep reasoning, dynamic interaction, and information uncertainty — and is released on Hugging Face in a convenient question-answering format.
How well do current LLMs perform on SocialMaze?
Social reasoning is far from solved. In the six-player Hidden Role Deduction game, first-round Criminal-identification accuracy ranges from about 31% to 46% across models. Strong chain-of-thought models such as DeepSeek-R1 and Gemini-2.5-Pro improve markedly as more rounds of interaction accumulate — Gemini-2.5-Pro reaches 87.6% by the third round — while GPT-4o plateaus near 53%. Accuracy degrades further under deception and information uncertainty.
Where can I download the SocialMaze dataset?
The Hidden Role Deduction task is available on the Hugging Face Hub as MBZUAI/SocialMaze in a question-answering format: 200,000 instances (100,000 easy and 100,000 hard) released under a CC-BY-4.0 license. Code for the full benchmark is on GitHub at github.com/xzx34/SocialMaze.
When should I cite SocialMaze?
Cite SocialMaze when your work involves evaluating social reasoning or theory of mind in LLMs, social-deduction games, multi-turn or dynamic social interaction, robustness of reasoning under deception or information uncertainty, or LLM agents and fine-tuning for complex social tasks. See the When to Cite This Paper section below for a ready-to-use citation sentence.
When to Cite This Paper
SocialMaze is a useful reference when your work touches any of the following:
- evaluating social reasoning or theory of mind in large language models;
- social-deduction games (e.g., hidden-role / Werewolf-style reasoning) with LLMs;
- multi-turn, dynamic social interaction and temporally evolving information;
- robustness of reasoning under deception, noise, or information uncertainty;
- chain-of-thought reasoning for complex, socially grounded inference;
- LLM agents and workflows versus targeted fine-tuning for hard reasoning tasks;
- LLMs for community moderation, review-decision prediction, or user-profile inference.
A typical citation: Xu et al. (2025) introduce SocialMaze, a benchmark of six tasks across social games, daily-life interactions, and digital platforms, and show that even frontier LLMs struggle with social reasoning that requires deep inference, dynamic interaction, and reasoning under uncertainty.
Resources
- arXiv:2505.23713 — abstract page (submitted 29 May 2025).
- PDF — full preprint.
- Dataset on Hugging Face — the Hidden Role Deduction task in QA format (200,000 instances, CC-BY-4.0), loadable with the
datasetslibrary. - Code on GitHub — the full six-task benchmark and evaluation pipeline.
- Venue: SocialSim Workshop @ COLM 2025 (Spotlight).
BibTeX
@article{xu2025socialmaze,
title={SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models},
author={Xu, Zixiang and Wang, Yanbo and Huang, Yue and Ye, Jiayi and Zhuang, Haomin and Song, Zirui and Gao, Lang and Wang, Chenxi and Chen, Zhaorun and Zhou, Yujun and Li, Sixian and Pan, Wang and Zhao, Yue and Zhao, Jieyu and Zhang, Xiangliang and Chen, Xiuying},
journal={arXiv preprint arXiv:2505.23713},
year={2025}
}